
Mire jó egy multilevel (többszintű) címkefelhő, amiben a címkék nagysága előfordulásuk gyakoriságát, színárnyalatuk pedig frisseségüket mutatja? Vegyünk egy példát.
Ha például rendelkezésünkre állna az összes amerikai elnöki beszéd, és valami okos szoftverrel a beszéd szövegéből címkéket gyárthatnánk (kiválogathatná a szövegekből az értékes kifejezéseket, megfeleltethetnénk egymásnak a különböző ragozott alakokat). Majd a kinyert értékes fogalmakat (címkéket) felvinnénk frisseség és előfordulásuk gyakorisága szerint egy ilyen multilevel címkefelhőbe. Na az klassz lenne.
Valahogy úgy nézne ki, hogy minden elnök minden beszéde egy-egy címkefelhőt adna ki, a címkék a beszéd főbb fogalmai lennének. A gyakran előfordult fogalmak nagyobb betűvel, és a frissebb fogalmak világosabb betűkkel jelennéne kmeg. Ugyan, ki csinálna ilyet?
Hát Chirag Mehta csinált. Annyival még megbolondította az egészet, hogy egy csúszkán nézhetjük végig, hogy az amerikai elnökök évenként tartott beszédeikben mit tartottak fontosnak, s mit kevésbé. Érdemes elidőzni az oldalon.
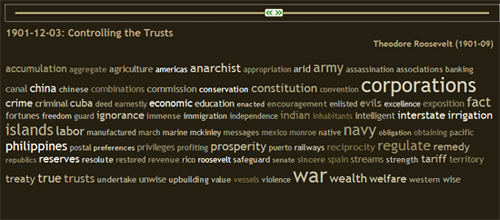
S világos lesz számunkra, hogy nem csak kiváló oktatóanyagokat lehetne készíteni ezzel a módszerrel, de egyben nagyon gyorsan, nagyon látványosan közölhetünk összetett információkat. Nem túlozzuk el, ha azt mondjuk, a címkefelhő újjászületését láthatjuk...
Ha például rendelkezésünkre állna az összes amerikai elnöki beszéd, és valami okos szoftverrel a beszéd szövegéből címkéket gyárthatnánk (kiválogathatná a szövegekből az értékes kifejezéseket, megfeleltethetnénk egymásnak a különböző ragozott alakokat). Majd a kinyert értékes fogalmakat (címkéket) felvinnénk frisseség és előfordulásuk gyakorisága szerint egy ilyen multilevel címkefelhőbe. Na az klassz lenne.
Valahogy úgy nézne ki, hogy minden elnök minden beszéde egy-egy címkefelhőt adna ki, a címkék a beszéd főbb fogalmai lennének. A gyakran előfordult fogalmak nagyobb betűvel, és a frissebb fogalmak világosabb betűkkel jelennéne kmeg. Ugyan, ki csinálna ilyet?
Hát Chirag Mehta csinált. Annyival még megbolondította az egészet, hogy egy csúszkán nézhetjük végig, hogy az amerikai elnökök évenként tartott beszédeikben mit tartottak fontosnak, s mit kevésbé. Érdemes elidőzni az oldalon.
S világos lesz számunkra, hogy nem csak kiváló oktatóanyagokat lehetne készíteni ezzel a módszerrel, de egyben nagyon gyorsan, nagyon látványosan közölhetünk összetett információkat. Nem túlozzuk el, ha azt mondjuk, a címkefelhő újjászületését láthatjuk...
Címkék: címke
27 komment
2006.11.04. 19:40. írta:
hírbehozó
gbrk · http://www.zhaoman.blogspot.com/ 2006.11.04. 19:57:50
Már csak egy olyan szover kellene, ami egyszerűen legyártja nekünk ezeket az infókat (akár offline szövegeinkből is)
hírbehozó · https://webisztan.blog.hu/ 2006.11.04. 20:00:37
Ferenc · http://online.blogter.hu 2006.11.04. 20:43:58
Lehet,h megvalósítás közben további problémákba ütköznénk, de alapelméletnek megteszi.
fotofabrik · http://fotofabrik.blog.hu/ 2006.11.04. 21:39:19
Benjamin · http://benjamin.blogter.hu/ 2006.11.04. 21:44:21
hírbehozó · https://webisztan.blog.hu/ 2006.11.04. 21:50:35
még egy ötlet: ajaxszal valós idejűvé tenni a kiértékelést.
mondjuk a nagy politikai hírszájtokra vetítve milyen szépen lehetne látni, ahogy a média rákap egy-egy politikus által kimondott szóra, meg úgy általában is: hogy mi a közbeszéd tárgya. érdekes lenne.
Ferenc · http://online.blogter.hu 2006.11.04. 22:10:19
blogter.hu/user_files/2296/hhtags.gif
tehát bekopizol egy szövget, megadod,h miylen írásjeleket és szavakat ne vegyen figyelembe, a maradékot pedig kitolja.
hírbehozó · https://webisztan.blog.hu/ 2006.11.04. 22:22:09
a frisseség mutatását hiányolom ebből a felhőből... attól lenne többszintű...
Ferenc · http://online.blogter.hu 2006.11.04. 22:24:45
Amit most mutattam, az csak egy alap. Pl egy téged érdeklő szöveget bemásolsz és látod a tageket, mint érdekesség. Tovább isfejleszthető akár:)
Lovik 2006.11.05. 08:35:02
Pl. szólhat egy teljes beszéd a fegyverkezésről úgy, hogy a "fegyverkezés" kétszer, a "nemzetközi helyzet", "fenyegetés" meg mondjuk ötvenszer fordul elő benne.
Benjamin · http://benjamin.blogter.hu/ 2006.11.05. 09:54:04
ha get-el meghivod vagy mas domainen levo url-t adsz meg akkor nullazza az adatokat, ha folyamatosan masolsz be egy oldalrol linkeket akkor dolgozza fel oket (idored + gyakorisag)
Szindbad 2006.11.05. 14:00:19
gbrk · http://www.zhaoman.blogspot.com/ 2006.11.05. 14:19:51
(Muszáj "élősködnöm, mert nem tudok programozni...)
Benjamin kezdő lépései nekem tetsznek. (a benjamin.hu-n nem tudtam kommentelni)
Benjamin · http://benjamin.blogter.hu/ 2006.11.05. 18:17:07
gbrk: mar lehet "kommentelni", a kapcsolat alatt megtalalod az elerhetosegem, keress meg, ird meg h. mire lennejo neked!
Pairg · http://pairg.atw.hu 2006.11.05. 19:17:02
users.atw.hu/pairg/?p=181
hírbehozó · https://webisztan.blog.hu/ 2006.11.06. 08:14:30
hírbehozó · https://webisztan.blog.hu/ 2006.11.06. 08:28:20
www.kottke.org/06/11/tag-frequency-and-popularity-acceleration
Mp3Pintyo · http://www.mp3portal.hu 2006.11.06. 10:11:26
Sajnos azt kell mondjam annyira nem egyszeru megoldani. A magyar nyelv nehezsegei igen sok fennakadast okoznanak a kivitelezes soran. A ragok, kepzok, stb eltavolitasa nem egyszeru feladat.
Amennyiben valaki komolyan neki akar allni mindenfelekepp vegye fel a kapcsolatot a magyar helyesiras ellenorzo fejlesztoivel. (ispell) emlekim szeirnt.
quitz · http://bodicsek.blog.hu 2006.11.06. 11:05:17
Nem itt van szerintem a kutya elásva. Automatikus tageléshez a relevancia becslését komolyabb statisztikai módszerekkel végzik, ami nem csak szavakat, hanem szókapcsolatokat is elemez. Jó tagekhez ismerni kell a forrás műfaját, jellemző szókészletét. A hierarchizálás sem jut túl messzire humán nélkül. Végül a tagelés ereje abban van, hogy a felhasználó szabadsága, a saját relevancia-struktúráit alkalmazza. Van akinek a hírolvasó szeme színe a fontos, és van akinek az amit mond. Nincs egyszerű recept, minden feladatra más hibrid kombót kell alkalmazni a tag és névtér logika keverésével.
hírbehozó · https://webisztan.blog.hu/ 2006.11.06. 11:26:55
ebben a felfogásban világosan látható lenne: a nagy, sötét és élénk címkék sokat hivatkozott, friss és releváns címkék.
meg akarom tudni, hogy mik a friss, egyelőre nem annyira felkapott, de releváns tartalmak?
nincs más dolgom, mint a pici, minél sötétebb és élénkebb címkéket szemügyre venni...
Karbonade · http://magyaropera.blog.hu 2006.11.06. 12:32:02
Cucu · http://kritikustomeg.org/ 2006.11.08. 02:31:40
kritikustomeg.org/szines_szagos_kulcsszavak.html
A cimkék nagyság mutatja, hogy hány ilyen film van (minél nagyobb, annál több), a színárnyalat pedig, hogy átlagosan milyen régiek a filmek (minél sötétebb, annál régebbiek).
Az például szépen látszódik, hogy a WTC mennyivel frissebb valami, mint a western. :-)
Sebesség okokból ez a multilevel cimkefelhő csak le lett generálva egyszer, a linkek pedig sima unilevel (rész)cimkefelhőkre mutatnak.
str 2006.11.08. 09:21:00
Krisz · http://www.tagcrowd.com/ 2006.11.14. 09:35:44
www.tagcrowd.com/
Benjamin · http://benjamin.hu/ 2006.11.22. 13:42:42
Benjamin · http://benjamin.hu/ 2006.11.22. 13:44:04
sajt · http://amon.hu 2006.11.22. 16:39:12