
Jakob Nielsen mérései szerint nagyon keveset. Egy átlagos netező egy átlagos weboldallátogatásnál a szavak 20 százalékát olvassa el. Akik kifejezetten olvasni szeretnének, azok sem olvasnak sokkal hosszabb textusokat. Náluk az arány 28 százalék.
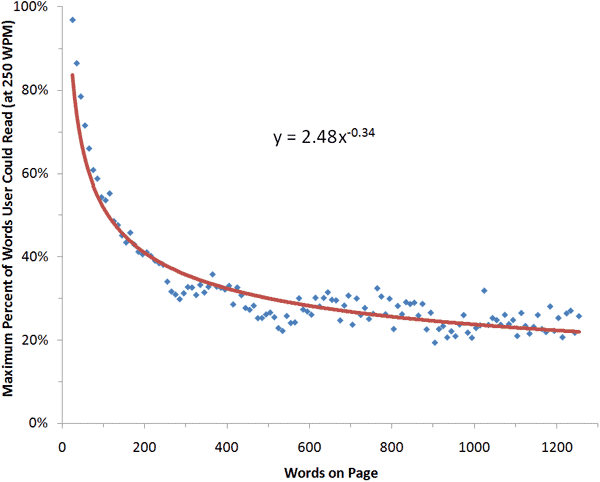
A grafikonból látható, hogy az olvasási hajlandóság már 100 szónál drasztikusan csökken. Ugyanakkor én mégis azt gondolom, hogy sokszor igenis van értelme hosszabb (sokszáz szavas) szövegeket is publikálni egy weboldalon. Miért? Hogyan? A belső címekkel, kiemelésekkel, képekkel lehet úgy törni a szövegfolyamot, hogy ne 400 szavas írásnak, hanem 4-szer 100 szavas írásnak tűnjön az olvasó elméjében.
Másrészt pedig az egy dolog, hogy az olvasók nagy százaléka lemorzsolódik 3 bekezdés után. A lényeg, hogy a szűk, lelkes kisebbség végigolvassa az egészet. És ha ez cél, akkor minden oké.
Persze általában azért igaz, hogy a weben sokat olvasunk: sokszor keveset.
(Ez a post 237 szavas. Vagyis tíz Webisztán-olvasóból 6 már nem jutott el eddig a mondatig.)
On an average visit, users read half the information only on those pages with 111 words or less. In the full dataset, the average page view contained 593 words. So, on average, users will have time to read 28% of the words if they devote all of their time to reading. More realistically, users will read about 20% of the text on the average page.Mi következik mindebből? Az amit mindig is hangsúlyozni szoktak webes szövegpublikálás kapcsán: röviden, tömören, lényegretörően. Úgy tűnik 111 szónál többet nemigen érdemes leírni egy weboldalra.
A grafikonból látható, hogy az olvasási hajlandóság már 100 szónál drasztikusan csökken. Ugyanakkor én mégis azt gondolom, hogy sokszor igenis van értelme hosszabb (sokszáz szavas) szövegeket is publikálni egy weboldalon. Miért? Hogyan? A belső címekkel, kiemelésekkel, képekkel lehet úgy törni a szövegfolyamot, hogy ne 400 szavas írásnak, hanem 4-szer 100 szavas írásnak tűnjön az olvasó elméjében.
Másrészt pedig az egy dolog, hogy az olvasók nagy százaléka lemorzsolódik 3 bekezdés után. A lényeg, hogy a szűk, lelkes kisebbség végigolvassa az egészet. És ha ez cél, akkor minden oké.
Persze általában azért igaz, hogy a weben sokat olvasunk: sokszor keveset.
(Ez a post 237 szavas. Vagyis tíz Webisztán-olvasóból 6 már nem jutott el eddig a mondatig.)
Címkék: média blogok usability
27 komment
2008.05.06. 16:37. írta:
hírbehozó
endorphyn · http://www.endorphyn.com 2008.05.06. 17:00:29
Amugy igen, tuti, hogy keveset olvasunk a weben, de szerintem ez annak a kovetkezmenye, hogy igy sokszor olyan dolgot is elkezdunk olvasni, ami valojaban nem igazan erdekel, csak egy pillanatra belekukkantanank, hogy mi is az. Igy ha valami erdekel, akkor altalaban hajlando vagyok vegigmenni rajta, de csak akkor, ha valoban megerint es erdekel. A tobbi meg csak "media-nyesedek" szamomra. Ez persze nem azt jelenti, hogy egyeb irant rosszak, csak szamomra nem jelentenek semmit.
szantog · http://szantog.com 2008.05.06. 17:01:20
Charybdis 2008.05.06. 17:09:46
potha 2008.05.06. 17:18:35
ChrisDry · http://www.chrisdry.com/ 2008.05.06. 17:23:15
Gál Kristóf | Primodesign · http://www.primodesign.hu/blog 2008.05.06. 17:26:25
Ardin 2008.05.06. 17:28:32
Másodszor a tartalmat nem különítették el releváns tartalom szempontjából, tehát a szavak számába a menüsor, a kommentek, az oldalsávon olvasható információk, tag-listák, korábbi bejegyzések, stb. stb. is beleszámított.
Érthetően elég kevés az az ember, aki végigolvas minden egyes betűt egy oldalon. A szavak számának növekedésével feltehetően az kevésbé releváns tartalmak mennyisége is nőtt. Elég csak egy hírportált megnézni. Elolvas az ember egy 10 soros cikket, viszont az oldalon van még 10x annyi szó. A hírt ugyan 100%-ban elolvasta, az egyebeket viszont semennyire. Az eredmény: a szavak kb 10%-át olvasta csak el. Azért ez nem ugyanaz, mintha a hír 10%-át olvasta volna csak el.
A harmadik gond, hogy ebbe az olvasási statisztikába például az információkeresés során meglátogatott oldalakat is belevették, amiket az emberek csak azért látogattak meg, hogy egyáltalán eldöntsék, érdekli-e őket az adott oldal. (a 4 másodpercnél hosszabb látogatást már érvényesnek tekintették).
Úgyhogy a 20 és a 28% átlagnak nem rossz, csak mint minden átlag, nem kevés torzítást tartalmazhat, illetve ebben az esetben bevallottan tartalmaz is. Egy szórást azért még írhattak volna mellé. Így azért némi távolságtartással kezelendő ez az adat.
dincsi · http://www.fotonlog.hu 2008.05.06. 17:43:04
Ha belegondoltok, az emberek (na jó én) a legtöbb esetben információforrásnak használom a netet. Egy problémára keresel megoldást, pikk-pakk kell, nem érsz rá hosszan olvasgatni. Sokszor egy weboldal közepéről egy magától értetődő kódrészlet kell csak, ilyenkor nem olvasod el az egész cikket.
Szóval egyszerűen a felhasználás más, mint egy újság esetében amit elejétől végéig végigolvas az ember.
Itt egy blogbejegyzés arról, hogy hogyan kell a webre megírni egy tartalmat hogy lehetőleg ne szaladjanak el a látogatók:
silicosaur.blogspot.com/2008/04/webes-publikcik-klszablyai.html
MiTortent · http://mitortent.hu 2008.05.06. 17:57:25
amondó (törölt) 2008.05.06. 18:17:31
eszpee · http://bp.underground.hu 2008.05.06. 18:24:22
Valakiember (törölt) 2008.05.06. 18:40:20
Nekem pl egy műszaki rajzánál is, ha kapok mellé egy magyarázatot, ami úgy 4-5 A4-es lapnyi szoveg, hát akkor inkább nézegetem a rajzot, és megcsinálom magyarázat nélkul pusztán a rajz alapján...
tresh 2008.05.06. 20:11:32
Tényleg így van. Gyakran nincs sok időm, de egy csomó blogot át akarok futni, olyankor tényleg csak szkennelés meg.
Viszont ha van időm, a kommenteket is elolvasom, mert gyakran abban jobb tartalmak vannak, mint magában a cikkben. :)
Galamb 2008.05.06. 20:47:07
-Thingol- · http://iTouch.hu 2008.05.06. 20:50:13
ijanos 2008.05.06. 21:43:36
Annyi információ áramlik be az rssolvasómba hogy csak kivonatolva olvasok. A végét inkább mint az elejét, slusszpoén: ha nem olvasom a kommentekben hogy van benne angol szöveg észre se veszem (megzavar hogy olyasmi színűszagúalakú az a box, mint egy reklámdoboz)
Planyo 2008.05.06. 21:59:20
Nekem az jutott eszembe, hogy most mindenki tudni akar mindent, amit a weboldalán, előtte, utána, vagy holnapután fog csinálni. De ez kezd őrület lenni. Néha nekem úgy tűnik.
Nem foglalkozott például a számítógépek előtt az író sem sosem azzal, hogy, hol, miért, mit olvas el a könyvéből az olvasó. Mondjuk eszköze sem volt sok hozzá.. talán odament a legközelebbi rokonlelkűhöz, és Jó napot! Megkérdezte. :)
atleta.hu · http://www.atleta.hu 2008.05.06. 22:44:54
Egyebkent annyira ez nem lehet meglepo: a tartalom mennyisege rohamosan novekszik, az idonk (a neten toltott ido) meg azert annyira nem.
nemethv · http://backtotheukblog.wordpress.com 2008.05.07. 01:30:35
Ugyhogy most lehet olyasmit írok amit más már megtett: szerintem itt van a kulonbség a hírek és a cikkek közt. Lásd pl Prohardver és társai (valamelyest az index is csak az nem tul szakmaias), ahol megjelennek a hírek amiket el lehet olvasni ha érdekel, rövidek, alkalmanként relevánsak de mindenesetre én legalábbis ami érdekel azt végigolvasom. Illetve vannak a cikkek/tesztek amik több oldalasak, és vagy az egész érdekes, vagy lehet benne szemezgetni.
Longhand · http://longhand.hu 2008.05.07. 02:26:33
Weboldal jellegétől függően persze eltérő, hogy mennyire szükséges hegyezni a tartalmat ezekre a részletekre és milyen arányokban.
Jakob Nielsen barátunk is pénzből él és tudja, hogy figyelemfelkeltőbbek lehetnek sokatmondónak tűnő általános megállapítások, mint az, ha egy alaposabb témaspecifikus tanulmányt közölne.
úrilány 2008.05.07. 04:37:25
illetve átugrott néhány bekezdést :P
bár végeredményben nem is olyan vicces a net olvasás és írás esetében is sajnos felületessé tesz :(
zfor 2008.05.07. 07:30:41
A cikk szerintem nem csak webre igaz.
MiTortent · http://mitortent.hu 2008.05.07. 10:31:07
hcpeter 2008.05.07. 12:49:50
Viszont megszoktam, hogy az egérrel kijelölöm az olvasott szöveget... pedig a könyvben nem mutatom újjal hogy hol tartok:)
ikse (törölt) · http://rollercoaster.blog.hu 2008.05.07. 18:39:01
Személy szerint, amelyik lap érdekel engem, annak minden betűjét elolvasom, akár többször is. Amelyik oldal, illetve cikk nem érdekel, azt nem olvasom el, maximum átfutom.
Üdv.
pollner · http://soreo.biz 2008.05.07. 19:33:49
Abban egyetértek, hogy az olvasási hajlandóság általában alacsony a weben, de a szkennelés mítoszát más kutatók már évekkel ezelőtt cáfolták. (Kb. fele-fele a szkennelők és az alapos olvasók aránya.)
A híreknél és hasonlónál nyilván nagy a lekopási arány, de ha az olvasó erősen érdeklődik a téma iránt (réteginformációk), sokkal nagyobb az esély, hogy eljut az írás végéig. (Nyilván ez a helyzet a Webisztán erősen elkötelezett olvasóközönségével is.) Csak írj nyugodtan hosszabban ezután is:)
István NagyRácz 2008.05.13. 13:11:41
Nagyon érdekes a fent említett anyag, bár meg kell mondanom nekem is vannak kétségeim a mérés körülményei felől. Elég sok olyan módszertani baki van benne így elsőre, ami megkérdőjelezi az eredményeket.
Egyébként a BME egyik tanszékén vagyok PhD-s és mi is foglalkozunk hasonló kutatásokkal. Jelenleg az egyik hallgatóm ír hasonló témában diplomamunkát. Ha valaki kedvet érez, hogy segítsen nekünk, akkor látogasson el a következő oldalra:
adatbanyaszat.tmit.bme.hu/~kovacszoltan/
Persze kérdések nekem is jöhetnek!
Üdv,
István