
Osztály vigyázz. Szakszerűtlen helyettesítés van.
Aki már korrektúrázott szkennelt, OCR-ezett szöveget, az tudja, hogy kevés lélekölőbb munka van ennél, és mindet szállítószalag mellett kell végezni. Az amerikai Carnegie Mellon egyetemen rájöttek, hogy ezt a feladatot nagyszerűen lehet elosztottan végezni. Nem teljesen automatizálva, ahogy ufókat és rákgyógyszer keresnek a hivatali gépek üres perceikben, hanem egy-egy felismeretlen szót captchaként felhasználva.
Az ötlet köré épülő szolgáltatás a reCAPTCHA nevet viseli, és az Internet Archive-on fellelhető könyveket segít digitalizálni. Regisztráció után jár hozzáférés az API-hoz, publikus és privát kulcs, pluginek az elterjedtebb CMS-ekhez, programrészletek, pénz, paripa, fegyver.
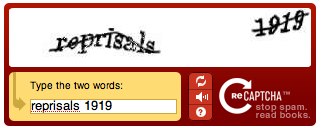 Azonosításhoz a reCAPTCHA két begépelendő szót ad. Az egyik megfejtése ismert, ezzel igazoljuk ember (vagy nagyon okos spambot) voltunkat, a másik pedig a világ haszna, egy morzsa egy nélkülünk eltűnő irodalmi műből.
Azonosításhoz a reCAPTCHA két begépelendő szót ad. Az egyik megfejtése ismert, ezzel igazoljuk ember (vagy nagyon okos spambot) voltunkat, a másik pedig a világ haszna, egy morzsa egy nélkülünk eltűnő irodalmi műből.
Mondanom sem kell, hogy a bennem lakó infóhippi határtalanul boldog. Még akkor is, ha a lassú külső szerverről töltődő captcha rendszert ebben a formában nem valószínű, hogy sokan fogják használni. Várjuk a v2.0-t.
(via TechCrunch)
Pas · http://pasthelod.hell-and-heaven.org 2007.09.17. 21:12:49
Pas · http://pasthelod.hell-and-heaven.org 2007.09.17. 21:17:29
Viszont akkor is, néha tényleg nagyon gány a szkennelt dolog :/
2007.09.17. 21:20:33
Aadaam 2007.09.17. 21:29:32
(Segitseg: spidermonkey: firefox grafikus kepernyo nelkuli, makrozhato valtozata gyakorlatilag)
A recaptcha egyebkent nem uj otlet, es foleg a konyvek hajtasainal levo szovegek feldolgozasarol szol (probaltal mar jo szorosan bekotott konyvet fenymasolni?). Nem hulyebiztos egyebkent, mert egyreszt feltetelezi, hogy az OCR program, ami az "ismert szot" scannelte, nem tevedett, masreszt hogy nem eresztenek ra egy masik OCR-t, ami az egyik szot felismeri (hiszen azt az eredeti is felismerte), a masikra meg ad egy random valaszt, elvegre ugyis csak az az ellenorzes targya, ami felismerheto.
Sz'al az otlet jo, csak gyakorlatban megvalosithatatlan: ha egy robot fel tud ismerni egy szot, egy masik robot is kepes lesz ra, authoritas meg nuku... :(
2007.09.17. 21:36:33
"egy-egy felismeretlen szót captchaként felhasználva."
ha jól értem, akkor velünk "javítanának". ha igen, akkor azt jelenti, hogy nem ismerik a szót, ezért íratják ki nekünk. ha nem ismerik, akkor honnan tudja, hogy jót írok be? vagy félreértek valamit?
2007.09.17. 21:38:50
human · http://yummie.hu 2007.09.17. 21:51:13
két szót kibogarászni meg sokkal jobb mint egyet, amikor így is alig lehet már elolvasni néha a captcha-kat
horvath_jano 2007.09.17. 22:00:23
Vagyis: máskor el vagyunk kényeztetve újdonságokkal :)
atleta.hu · http://www.atleta.hu 2007.09.17. 22:09:36
ze11 2007.09.17. 22:10:25
Nem tűnik fel, hogy a linkelt oldalon a felismerendő szövegek egyike sem néz ki scannelt szövegnek!?
zsolti 2007.09.17. 22:11:01
softcore 2007.09.17. 22:39:33
Amúgy a dolog az eddigi captcha-k helyett működne és ebben ki is merülne a funkciója. Tehát nem öncélúan használnák az önkéntesek, mint pl. a Google Image Labelert.
softcore 2007.09.17. 22:41:51
is 2007.09.17. 23:03:16
a kihasználás (beírt CAPTHCA megy a másik oldalra) lehetséges, de ezen túl javítok: az ismert szót NEM a scannelt szövegből adják, hanem a saját szótárukból (vlsz. az a szám, amit on-the-fly is lehet generálni).
érdekes, nekem a poszt képén a reprisals bizony scanneltnek tűnik (r-ben festékkarika, a jobb szára homályos, p talpa festékhiányos stb.)
meroving 2007.09.17. 23:39:23
horvath_jano 2007.09.18. 00:07:34
Szedlák Ádám · http://worldshots.hu 2007.09.18. 08:49:38
My bad, nem rémlett, hogy ezt már egyszer körbejárta a sajtót.
@zsolti
Szótalálgatós mashup még nincs, van viszont - igaz, csak IE alatt működő - digitalizált Váradi Regestrum borzalmas minőségben:
www.rfmlib.hu/digitkonyvtar/dok/vr/index.html
Pedig intellektuális kalandnak megtenné.
kutacs_ (törölt) 2007.09.18. 09:22:47
emberibbé kell tenni a kommunikációt a közösségi szolgáltatások építésekor. és akkor nem kell captcha. a fizetős szolgáltatásokra meg nem buknak a botok.
a könyvekben a javítgatást sem kell túlbonyolítani. oda kell adni a népeknek, akár a spambotnak, h nesze olvasd, itt az eredeti, itt az ocr változat, aztán ha gondolod javítsd ki. ha sokat javítottál kapsz egy pólót, meg még a csajodnak is adunk egyet, ezt a hirdetések árából fedezzük aztán szevasz. vagy össze kell kapcsolni olvasói klubbal, stb, stb.
Pas · http://pasthelod.hell-and-heaven.org 2007.09.18. 18:20:15
valószínűleg a szpemmerek is emberek, csak szeretnénk azt hinni, hogy kicsit mégse :C
atleta.hu · http://www.atleta.hu 2007.09.19. 02:48:15
kutacs_ (törölt) 2007.09.19. 09:35:19
tök jó dolog ez a recaptha. a carnegie mellon egyetemen ültek a srácok és a lányok aztán és ez jutott eszükbe. csináltak egy weboldalt, szóltak, h írja már meg valaki a techcrunchba, és akkor ez hh által eljut ide. ez teljesen rendben van.
csak nézzük már meg, h mi a probléma. vannak olyan könyveink, folyóirataink, amelyek nincsenek meg elektronikus változatban, és jó volna ezeket digitalizálni. a könyvek többsége ugye ma már nincs kereskedelmi forgalomban, nem a harry potterről van szó, tehát senkinek az érdekeit nem sérti, ha ezeket a könyvtárak digitalizálják. a könyvekhez venni kell egy rakás v alakú scannert, a folyóiratokhoz jó a lapos. majd rá kell ereszteni egy ocr olvasót, majd a az olvasót. akik majd a meglévő szöveget kijavítják. nyilván az összes verziót meg kell őrizni, ha valaki véletlenül vagy szándékosan rongál, akkor visszaállítható legyen egy korábbi verzió. nem hiszem, h eddig bármi újat mondtam volna a blog olvasói 100%-ának. tehát nem kell hülyének lenni, ehhez nem kell recaptha. lehet az is, de ettől várni idehaza a nagy eredményt hülyeség. először is hány captcha szerverünk van.
másrészt errefelé a népek nem nagyon lelkesek, illetve akik lelkesek, azokat régebben üldözte a rendőrség, ezért valami egyszerű hirdetési felületet is kell csinálni, h az olvasók érdekeltek legyenen a javítgatásban. itt már csak 10%-os egyetértés van. mert ilyenkor a többség azt mondja, h nehogy már a közkönyvtárak oldalain célzottan hirdessenek, jaj, jaj, mi lesz. nem lesz semmi, meg lehet fizetni a könyvtárost, és az olvasót. meg kell egy főszponzor, h legyen egy induló alap. nyilván azonnal szponzorálna egy ilyen projektet az adobe, h mondjuk pdf-be menjen már minden.
és egy harmadik gondolat. mivel errefelé most liberális demokrácia van, ami szintén tök jó dolog. és innentől kezdve már csak 1%-os egyetértés szokott lenni. ezek a dolgok akkor fognak megvalósulni, amikor az irodalmi és a techno közösség bemondja, és minden fórumon megírja a megoldást, az és-ben, az index-en, az origo-n, a kultúrházban, tudom is még hol. h ezt a problémát így és így kell megoldani.
amíg csak csapkodjuk a térdünket, ha valamit látunk a techcrunchban, vagy bárhol, addig történik semmi. nem lesz párthatározat. gyurcsány és orbán nem kádár, hiller és magyar bálint nem aczél györgy. szerencsére. vagy a fene se tudja.
atleta.hu · http://www.atleta.hu 2007.09.19. 13:52:28
Abban is igazad lehet, hogy ha sok konyvet scannelsz, akkor erdemes specko scannert hasznalni, ami sokkal kevesebb hibat fog eredmenyezni (bar megint kerdes, hogy az mekkora befektetes - en nem tudom).
Abban mar nem ertunk egyet, hogy bescanneljuk, aztan majd az olvaso javitja. Ahogy mondtam, az kevesebb emberre terhelne tobb munkat, lassabb lenne a haladas. Es az OCR lenyege nem csak az, hogy kevesebb helyet foglaljon az a konyv, hanem az is, hogy _keresni_ lehessen. Minel elobb, annal tobben fogjak latni. (Jo reszben igy is lehet, mert nyilvan csak nehany szo hianyzik oldalankent.)
Azt viszont vegleg nem ertem, hogy attol miert szar az otlet, mert szerinted nalunk nem mukodne jol (sztem sem tul valoszinu). Ott mukodhet jol, ettol meg tetszhet, kesz ennyi. A vilagon tobben beszelik az angolt, ebbol kovetkezoen sokkal tobb embert lehet ebbe felig onkentesen bevonni. Magyarul is meg lehetne porbalni egyebkent. Meg kell becsulni, hogy hany captcha-t oldanak meg magyar oldalakon, es abbol kiderulne, hogy van-e ertelme (hogy van-e ra szukseg, az mas kerdes). Ha nincs capctha szerver hat majd csinal(nanak) egyet a cel erdekeben. De tenyleg nem letom be, hogy egy kulfoldon kiprobalt jopofa otletet miert kell leszarozni azert, mert talan itthon nem mukodne.
kutacs_ (törölt) 2007.09.19. 14:37:47
még 1x. nem azzal van a bajom ami van, hanem azzal ami nincs.
nem szar az ötlet, csak azt gondolom, h itt a megoldás középszinten van. ebben a témában arról kellene írni, h a könyvtárasok a kereslet függvényében scanneljenek, az olvasók meg a kínálat függvényében javítsanak az eredményen.
ehhez semmiféle különösebb ötletelés nem kell, hanem némi pénz, pénz ami ösztönzi a könyvtárost és az olvasót. és ennek a pénznek a piacról kell jönnie, részben a helyi hirdetési piacról, részben a globális szoftverpiacról. itt az adobe lehet az elsőszámú partner, mert akkor mehet minden pdf-be. vagy a google, a gbooks projektbe bekapcsolódni. vagy a ms aki állítólag tudástársadalmat akar, ezt reklámozzák, vagy az oracle aki a könyvekre, folyóiratokra vonatkozó metaadatokat tárolja. erről kellene beszélni, azt mondani, h itt egy probléma, és akkor ez a megoldás. aztán még kellenek eszközök, mert azokat a szkennereket, meg a terrabájtokat meg kell vásárolni, erre van kitalálva a nemzetközösség, az unió, és akkor ők megvennék az eszközöket szívesen, ha mondjuk a magyar kulturális és techno szakma csinálna valamit. csak ugye ez a szakma itt nagyjából úgy működik, mint a többi, várja, h történjen valami.
szerintem ez a dolog sokkal egyszerűbben is működik, vagy működne, minden tiszteletem a carnegie melloné. nyilván a két felfogás nem zárja ki egymást.
amúgy ha itt tartunk, a captcha-t lehetne módosítani úgy, h kitesz egy szót valamelyik könyvből, aztán olvasd el, és ha nem sikerül eltalálni, akkor kapsz egy újabb másik lehetőséget. feljegyzi a választ, aztán ha külön ip-kről egybehangzóan állítják, h oda mégsem az van írva, hogy "bokréta", hanem h "atleta", akkor elfogadja, h oké, legyen "atleta".
de lehet ilyen repatcha is, amelyik így kipárosítja a biztost és a bizonytalant, és mindkét szót jól behullásmosítja, teleszemeteli, és áthúzza, nehogy felismerje a gép. szerintem ez a megoldástól való eltávolodás, és egyszerűbb megoldások léteznek. persze mennél bővebb az eszköztár, annál jobb.
atleta.hu · http://www.atleta.hu 2007.09.20. 02:09:39
De hat az tok masoknak a feladata! Meg infrastrukturalisan macerasabb is, lassuk be. ettol fuggetlenul igen, az tok jo lenne. De ahogy te is irod lentebb, ezek nem zarjak ki egymast. Nyilvan ha az altalad javasolt megoldas mar mukodne, akkor nem talaljak ezt ki a CMU-n. Talan oket is zavarta, hogy nem igy van, es ez adta az osztonzest :)
> de lehet ilyen repatcha is, amelyik így kipárosítja a biztost
> és a bizonytalant, és mindkét szót jól behullásmosítja,
Kenytelen, hogy kiszurje a tippelo botokat. Ha csak emberek fejtenek, akkor nem kene ketto, eleg lenne egy. De ha nem lennenek botok, nem kene CAPTCHA sem :)
> teleszemeteli, és áthúzza, nehogy felismerje a gép. szerintem
> ez a megoldástól való eltávolodás, és egyszerűbb megoldások
> léteznek. persze mennél bővebb az eszköztár, annál jobb.
Ez eleg egyszeru. Nem kell hozza unios penz, meg uj szkennert venni, meg konyvtarosokat pluszban tornaztatni. Par egyetemista osszedobja nagyhaziban a mukodo megoldast. Nekem pont a partizan jellege tetszik az otletnek. Meg persze a pigybacking, hogy alig ad plusz munkat a tarsadalomnak, szinte ingyen van. Ez egyszeru. Az, hogy egy szamitogep hullamosit meg athuzogat nehanymillio kepet, az nem tema, nem komplikacio.
Ha meg kel gyozni nehany illetekest, hogy nem ugy kene, hanem igy, na _az_ a macera :). Es ahogy irtad, ettol meg ugyanugy lehet lobbizni erte, mint eddig. A ket dolog fuggetlen egymastol. Ha nem lesz erre szukseg, az csak jo lesz. Amig meg van, addig ez egy olcso megoldas.